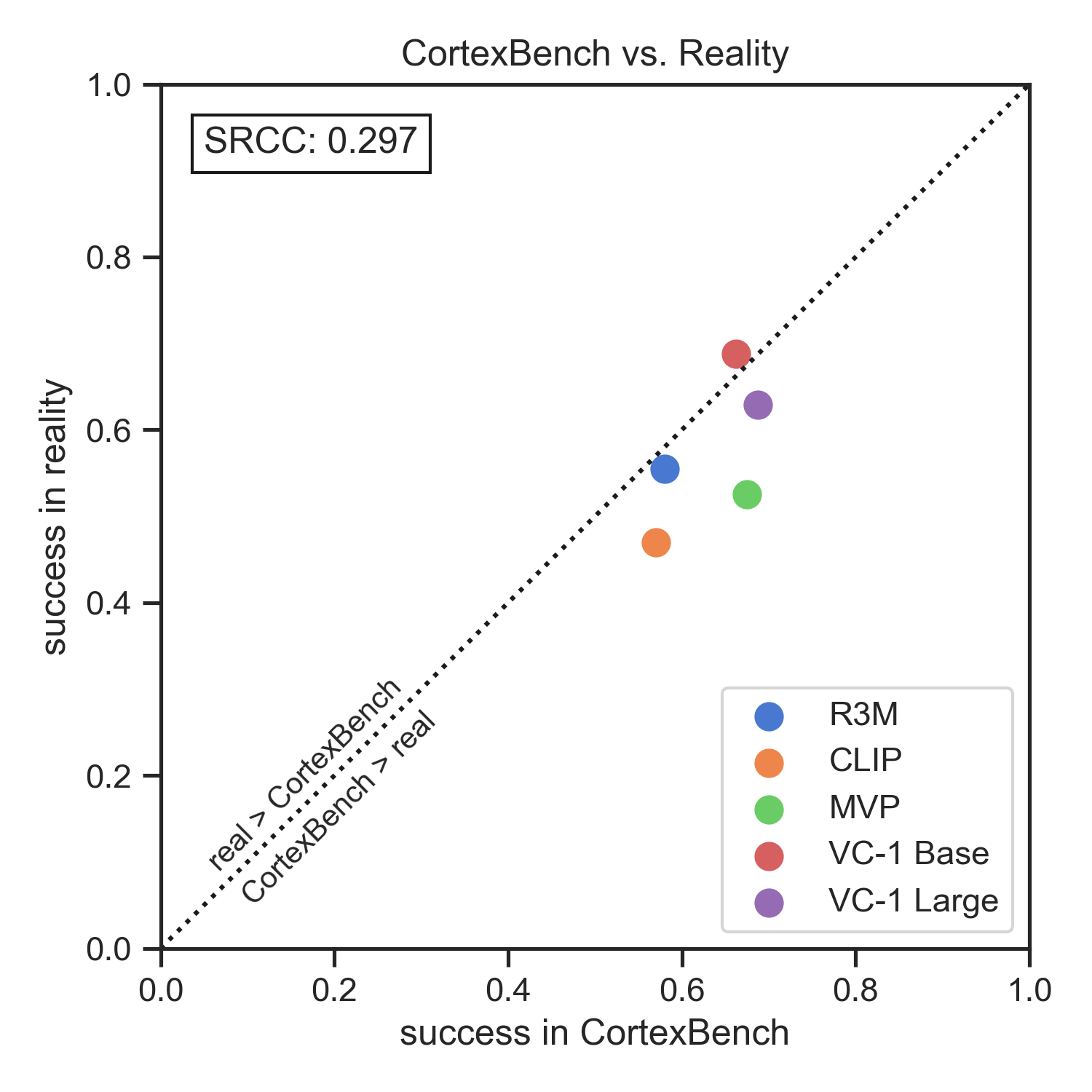
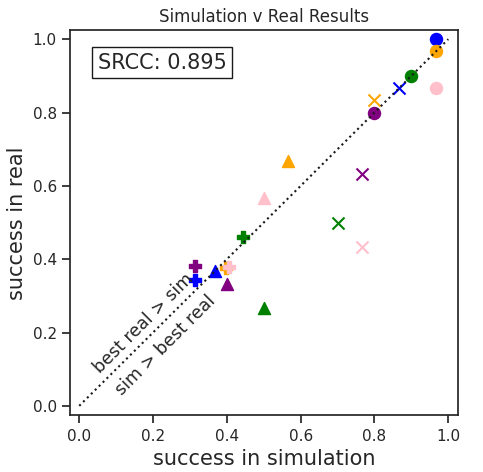
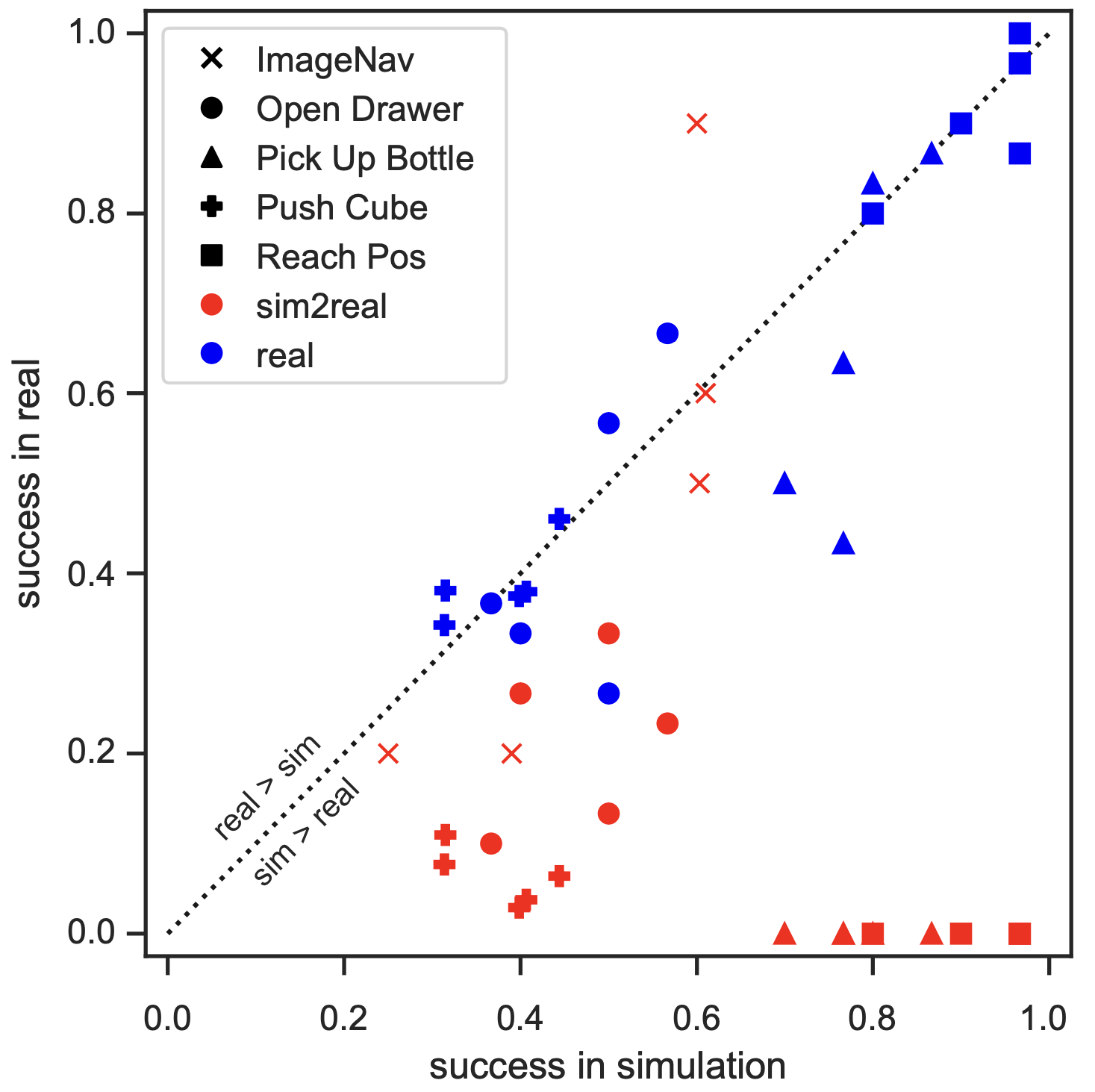
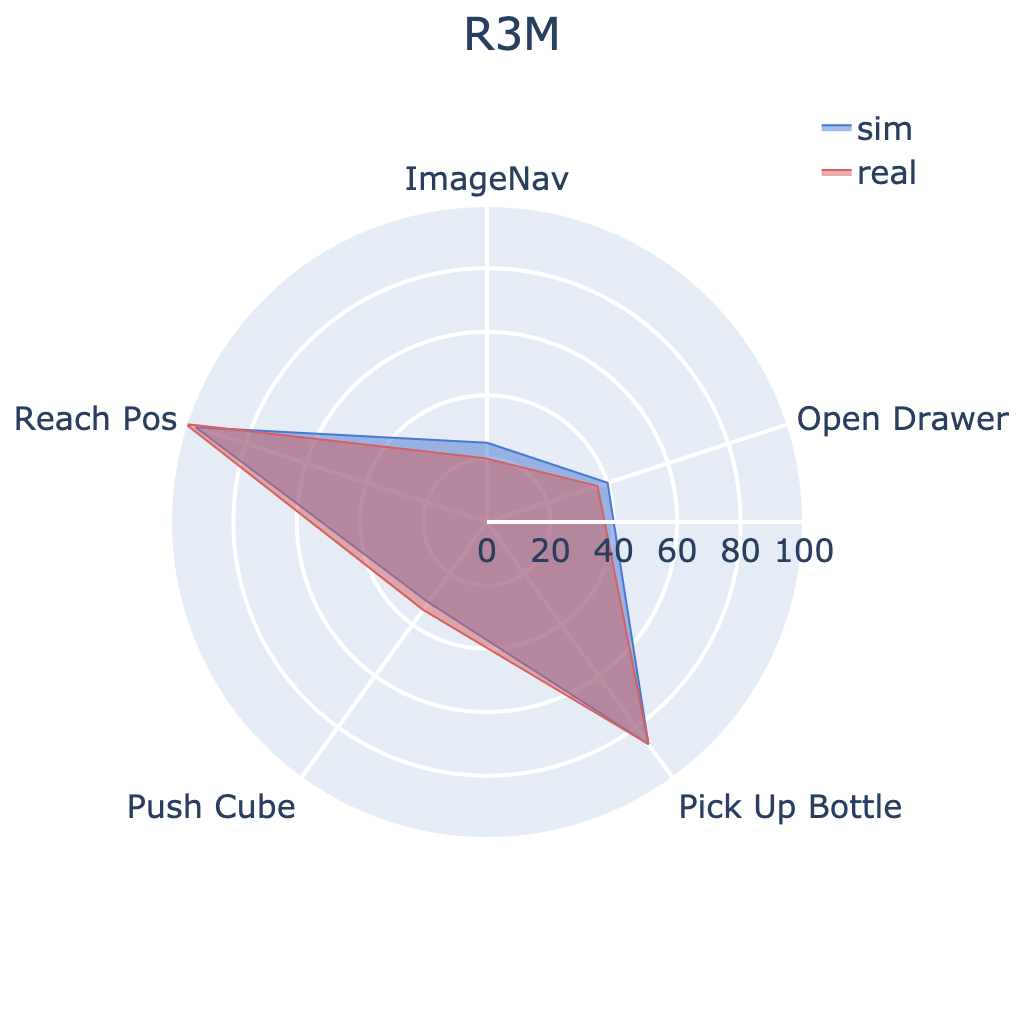
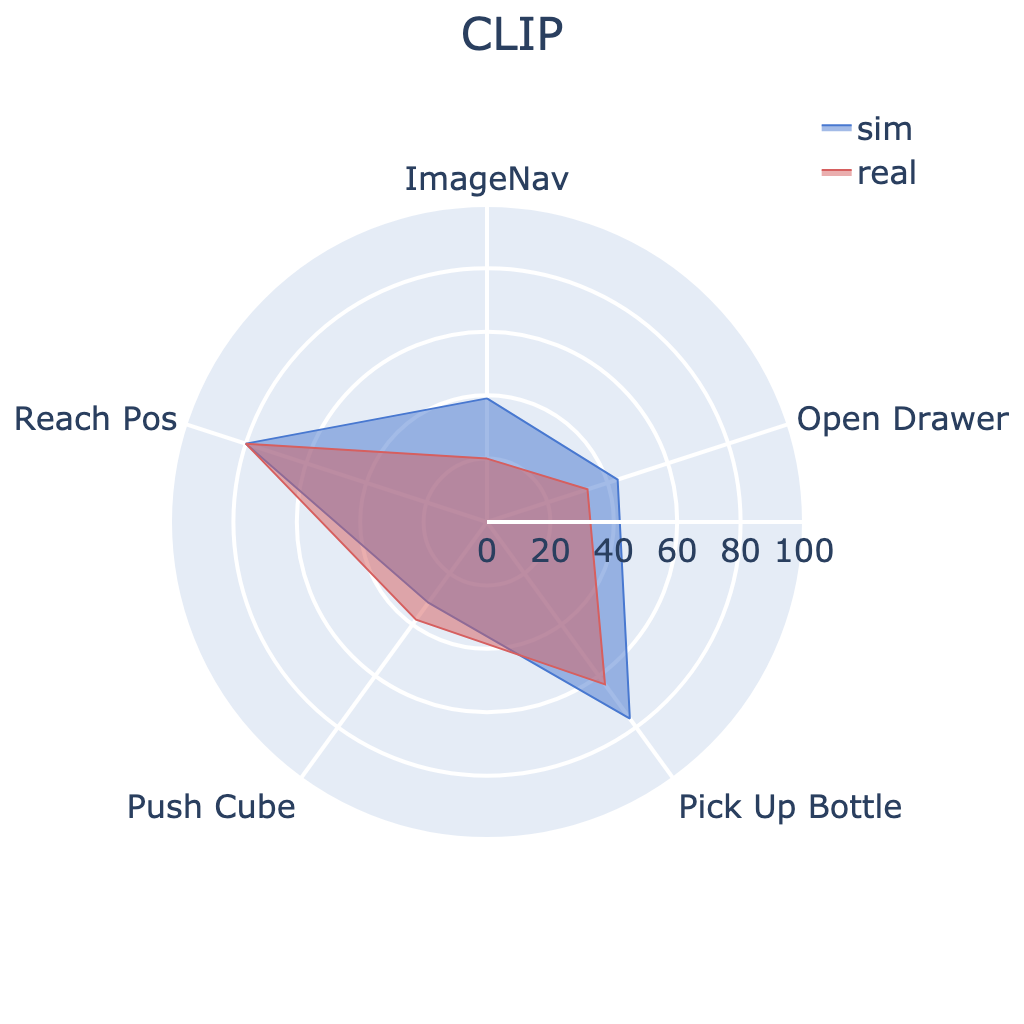
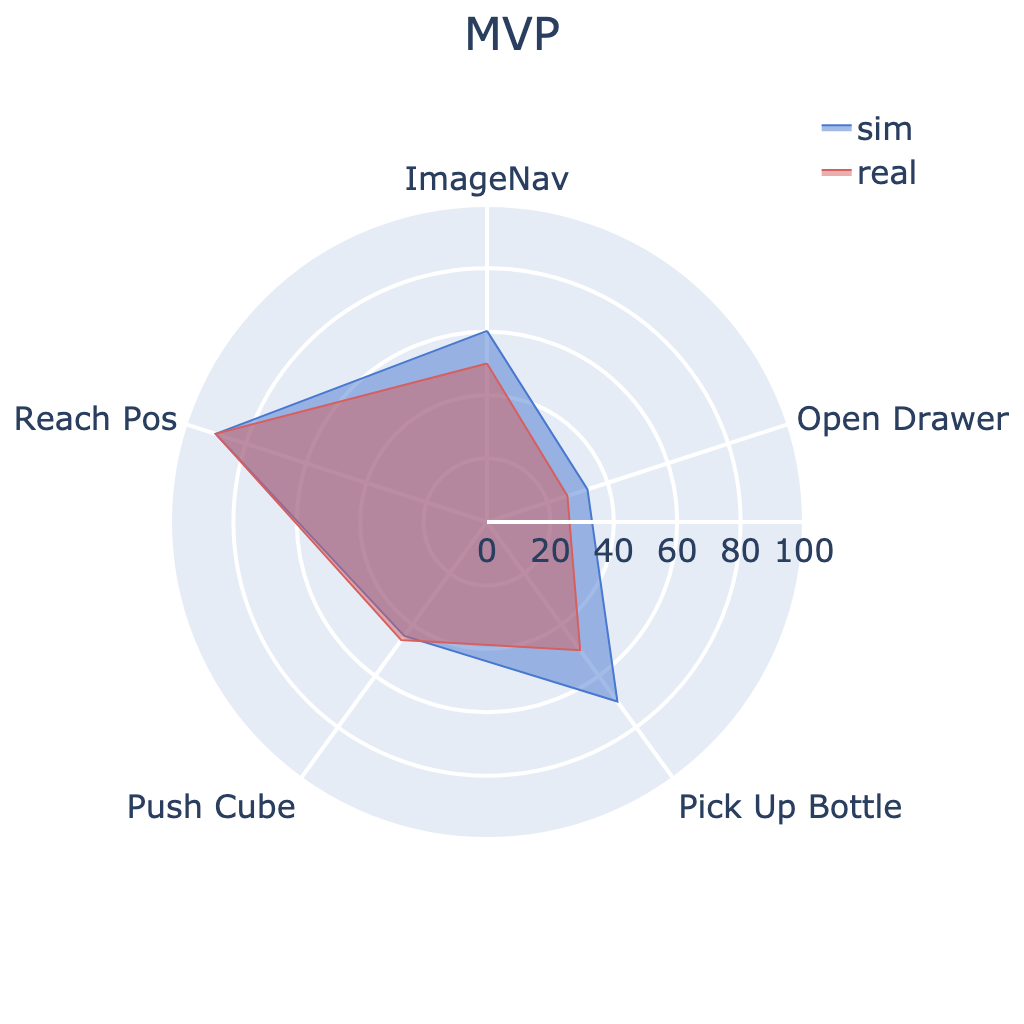
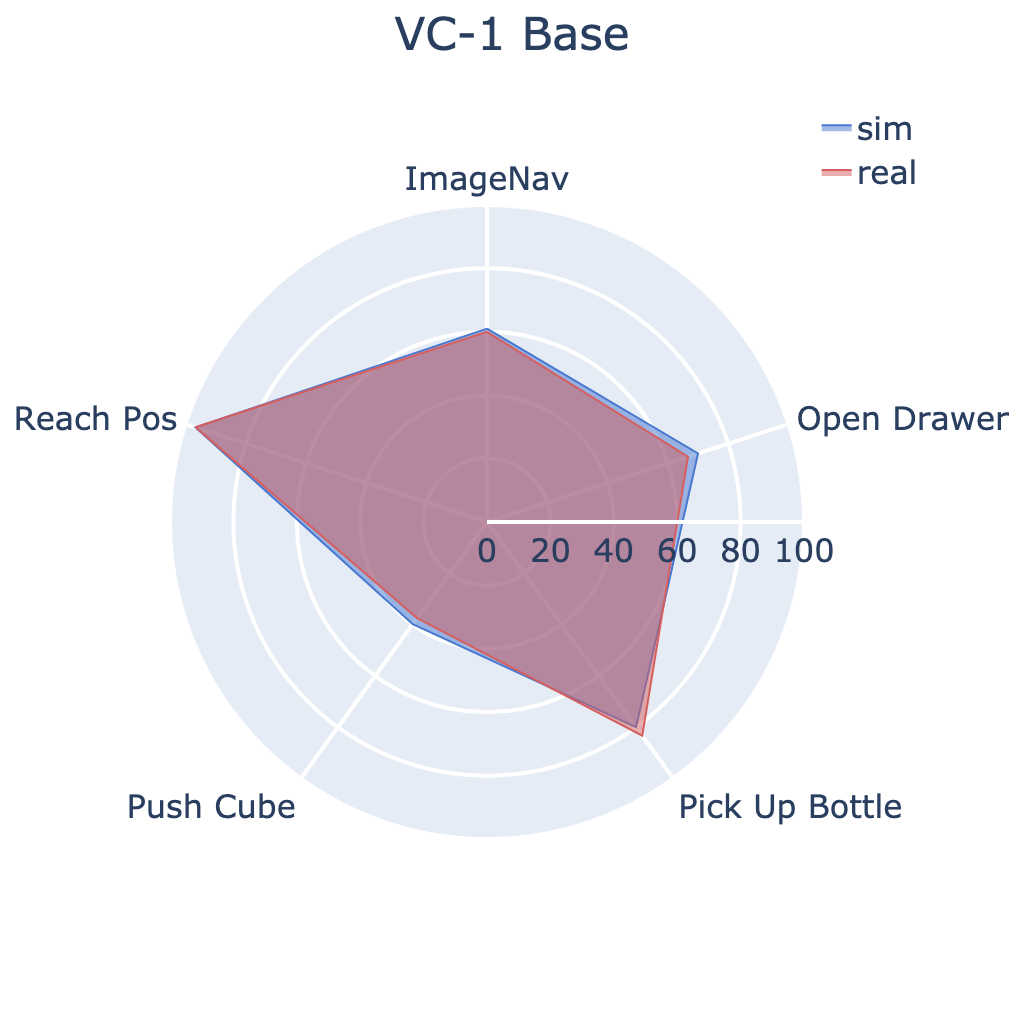
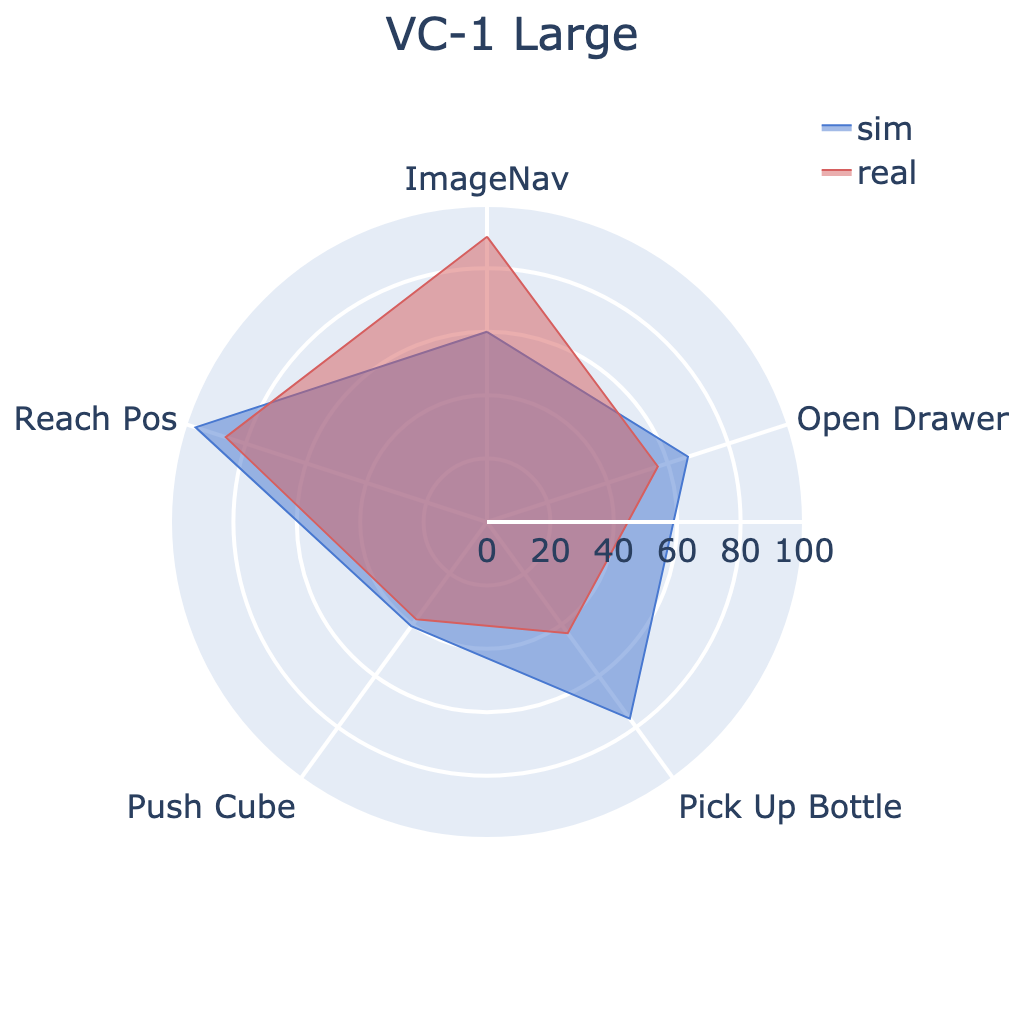
Our large-scale empirical study has significantly advanced the understanding of
pre-trained visual representations
(PVRs) in robot learning. We found a high degree of sim2real predictivity of PVR-based
policies, suggesting that
simulation experiments can inform real-world performance. Furthermore, we have achieved
a landmark result on ImageNav,
demonstrating the critical role of PVRs in enabling effective sim2real transfer.
Finally, our study highlights the impact
of key design decisions, such as model size, data augmentation, and fine-tuning when
deploying PVRs in real-world robotics
tasks. These insights help illuminate the immense potential of PVRs for robot learning,
setting a strong foundation for
future research.
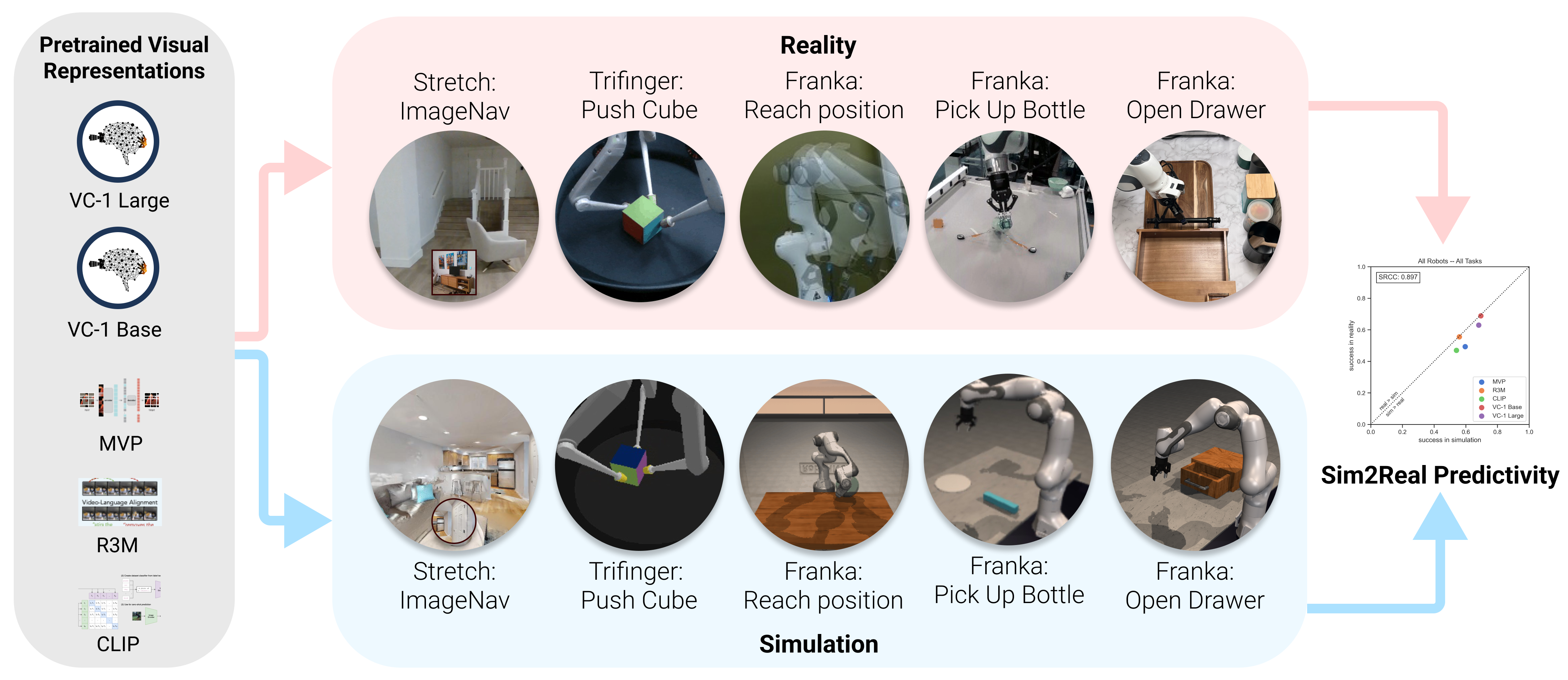 We conducted 304 experiments with PVRs on five tasks (push cube, pick up bottle, open drawer,
reach goal position, and image-goal navigation),
three robots (Trifinger, Franka, and Stretch), two learning paradigms (imitation and
reinforcement learning), in simulation and reality.
We conducted 304 experiments with PVRs on five tasks (push cube, pick up bottle, open drawer,
reach goal position, and image-goal navigation),
three robots (Trifinger, Franka, and Stretch), two learning paradigms (imitation and
reinforcement learning), in simulation and reality.